How to write an Incident Postmortem (with example and template)
When an Incident gets fixed and its tracking ticket is closed, that is only the halfway point in the Incident Management process. Afterwards comes the work needed to write a postmortem document and conduct a postmortem review meeting.
Purpose of a postmortem document
Writing out a multi-page detailed postmortem document can feel like busywork — however the postmortem is the most important part of the Incident Management process. It may be tempting to settle into a mindset thinking that fixing the incident is the important part, since restoring service by bringing a platform back into working order feels critically important in the moment. But in a paradoxical turn, fixing the incident is the least important step since that lies in the short-term and will barely be remembered in the long-term.
A postmortem is about fixing as many future incidents as possible before they even happen, and the rigor of a postmortem process dictates the trend of the frequency and magnitude of incidents in the long-term.
A single incident is a part of business, but incidents have a bad habit of repeating themselves if the underlying root cause isn’t clearly identified and remediated. No one will remember the 29 minute SEV1 from three years ago,.. if and only if it did not resurface and become a repeated event. Repeated events are memorable, and those can ruin trust in a platform. If customers can’t depend on your service then they will find alternatives in the long-term.
Example postmortem (and template)
Oftentimes it helps to have a clear example of the desired outcome to learn what to work towards. So let’s start off with an example postmortem: 2020–01–13 — SEV1 Checkout was broken (this is a fictional incident, any resemblance to an actual incident is coincidental) and a base template: 20YY-MM-DD — SEVx <incident title>.
Working from that example we can walk through a number of the key pieces of constructing a robust postmortem document.
Collect all the data
First thing as soon as the incident is closed (and even during when reasonable), collect all of the data possible. During the incident take a screenshot of the user experience, of dashboards, of deployment pages, etc.. take screenshots and make copies of every key piece of data potentially related to the incident.
The nature of postmortem documents is that their longevity is critically important — these documents should be readable for an exceedingly long time, their lessons learned can be relevant for reference and study for several years. This means that a postmortem document needs to be self-complete. While hyperlinks to all of the related systems like dashboards, traces, logs, etc.. are wonderfully useful while those links still work each of those systems has a data retention limit and each of those pages will stop displaying data. Depending on the policy some data will be eclipsed in as short as 14 days.
So, make copies of the data as soon as reasonable to put into the postmortem.
Write down a granular timeline
Don’t skimp on the details in the timeline, indeed whenever possible every row in the timeline should link to a reference (metric, deployment, PR, etc..) and have as accurate a timestamp as possible.
A detailed timeline is the heart of a postmortem. Every other part of the doc revolves around the precise time and a clear accounting of each event. The root cause is often illuminated by carefully reviewing the timeline and order of events, and action items are usually designed to shorten the time elapsed between key events.
Blame process, not people (aka: blameless)
People are human, and you should always assume that humans have non-zero chance of making a mistake when performing any action. Sufficiently robust software can repeat the same action practically indefinitely without faltering, humans on the other hand can at best get through a few thousand iterations at best before making a flub of one kind or another. It does not matter what the action is, humans will reliably error at a non-zero rate.
Creating software to provide guardrail protections against every human action is intractable even for the largest of companies (cite: 2021 Facebook outage). Therefore the question is the degree to which a human induced error rate is acceptable for the particular business that a platform supports.
The corollary of this is that people are blameless of incidents — leaving software corrections and process improvement as the only objectives of the postmortem.
Digging deep with “5 Whys” root cause analysis
In order to know what to do after an incident first you must have a clear and deep understanding of what caused the incident. This is done using the 5 Whys technique to analyze the precise root cause. 5 Whys was originally described at Toyota for purposes of analyzing why new features or manufacturing processes were needed. Since that time they have been adapted as a technique for root cause analysis.
In combination with the 5 Whys, the Swiss cheese model is a second framework for thinking about how incidents occur. In the Swiss cheese framework you describe systems like they are layers of Swiss cheese, where any given layer that attempts to protect the platform may have gaps (or holes in the analogy) and an incident is likened to the chance that at some point the holes in all the layers line up letting something nefarious pass through. The layers come in 3 categories: immediate causes, preconditions, and underlying causes.
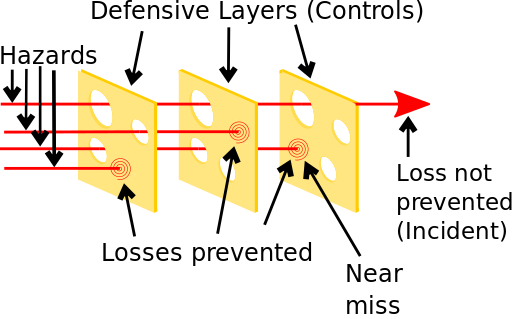
The two models merge together when thinking through the list of the Whys. Each Why should tell the story of the incident by forming layers that start with the user and get deeper into the system with each Why. This will generally follow this pattern:
- The first 1 or 2 Whys will be related to immediate causes and describe the direct user-facing parts of the incident
- The middle Whys will walk through the set of preconditions that allowed the failure to happen by connecting the triggering event with the deeper cause
- The last 1 or 2 Whys will highlight underlying causes (there may be more than one!) which lay latent in the system
A few notes about 5 Whys:
- Every Why should be materially different from the Why that came before and after it in the list, you do not get to repeat yourself.
- The number of 5 is a guideline as some incidents deserve additional Whys in order to fully tell the story of the incident, but note that 5 is a minimum.
- The first 1 or two Whys that detail the immediate causes may have shorter explanations and be fairly straightforward connections to the deeper story, however each deeper Why in the list should get progressively more detail. The last Whys describing the underlying causes should have complete details and in some cases can occupy fairly lengthy descriptions (just remember that if it gets too long that is an indicator that the Why may be suitable to getting split into multiple Whys).
To spur thoughts on writing detailed in-depth “Whys”. Here is a framework (that should not be used blindly) that illustrates a common pattern that many incidents follow:
- Why were users impacted? Because technical feature X was broken for users.
- Why was technical feature X broken? Because backend service Y was broken.
- Why was backend service Y broken? Because there was a bug in the service that caused it to break.
- Why was there a bug? Because the code was not implemented properly and pre-production testing did not catch it.
- Why didn’t the system auto-heal? Because the way this failed did not trigger the automatic safeguards.
How to think about action items
Action items are the end result of all of this hard work. They capture a list of things that can be worked on to improve the system to reduce the chance of future incidents. In many ways all of the rest of the postmortem document builds up into the list of action items. The detailed data, timeline, and 5 Whys are each important precisely because they are the inputs into the formulation of action items.
A good postmortem action item list will take an iterative approach and itemize a clearly identified round of improvements that improve the resiliency of the system by “one notch” (aka the amount deemed practical). This isn’t the time to go overboard and consume unlimited bandwidth to make any change imagined, care should be taken to understand the core issues and the tradeoff of effort contrasted with impact. Postmortem actions are special in the roadmap planning process because they take unique priority over other activities and are injected tasks into sprints. This is a powerful tool that should be leveraged with balanced weighting to make the system better.
To compile a set of complete action items start by reviewing:
- Each of the “Time to X” intervals in the timeline summary and ask: “How could this be shorter?”
- Each “Why” in the root cause analysis and ask: “What could have prevented this or caught this earlier?”
- Each “What did not go well” and ask: “How could this have gone better?”
- Each “Where we got lucky” and ask: “Is there anything we can do to improve and depend less on luck next time?”
With all of these questions in-mind, think about these types of actions:
- Prevention — How could we get ahead of future incidents and prevent issues before they happen?
- Detection — Can we detect that the incident is about to happen? Are we missing any alarms, need to tune alarm thresholds, change alarm severity, etc..?
- Acknowledgement — Did we respond timely? If not, how can we improve our oncall procedure to get faster?
- Mitigation — Were we able to identify a potential root cause quickly and able to take mitigating action quickly?
- Communication — How was our communication both internally and externally?
- Documentation — Anything we should write down in our docs as a result of lessons learned here?
A complete guide to Incident management
This article is part of a series on Incident management, which includes:
- Incident severity levels for online platforms
- A guide to running Incident Command
- How to write an Incident Postmortem (with example and template) (this article)
- How to conduct a postmortem review meeting
- The importance of SEV-1 call leaders
